✦ VFM, LLM and VLM in the Medical Domain Large Models
Large-scale pretrained models are reshaping medical AI — replacing task-specific pipelines with unified representations that generalize across organs, modalities, and clinical tasks. We build and adapt visual foundation models, large language models, and vision-language models for medicine, covering pretraining strategies, efficient finetuning, and rigorous clinical evaluation.

Visual Foundation Models
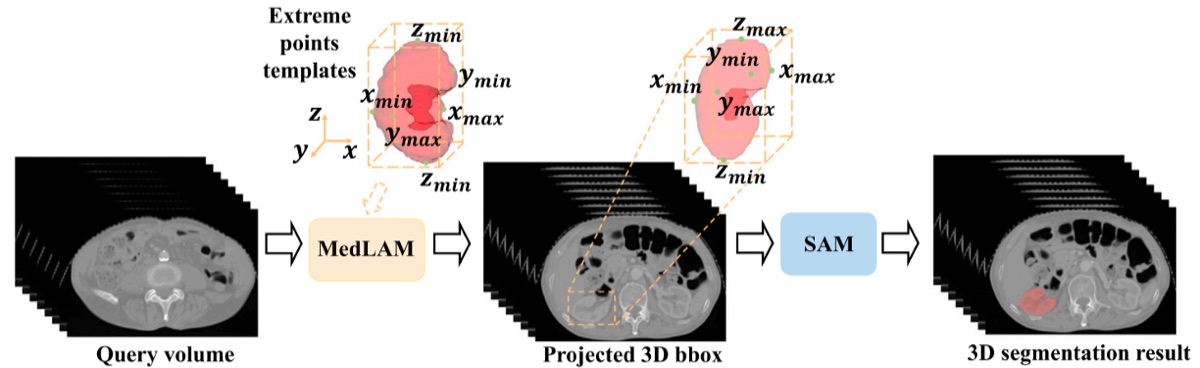
MedLSAM: Localize and Segment Anything Model for 3D CT Images
Extends the Segment Anything Model to 3D medical imaging by introducing a localization prior that guides mask generation in volumetric CT scans, achieving strong zero-shot segmentation across diverse anatomical structures.
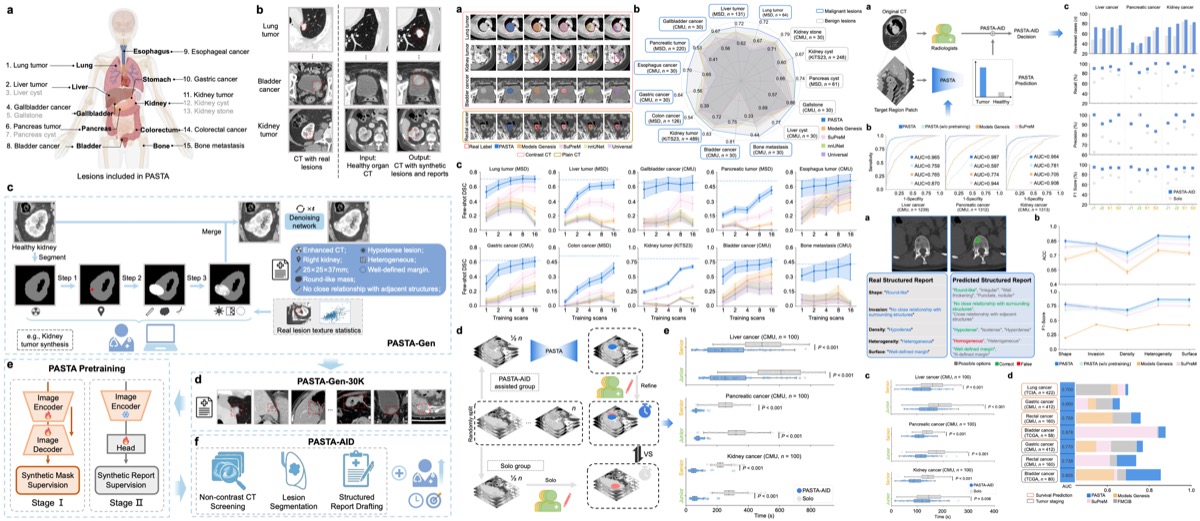
A Data-efficient Pan-tumor Foundation Model for Oncology CT Interpretation
A foundation model for oncology CT that achieves broad tumor coverage with significantly reduced annotation requirements, enabling scalable pretraining across heterogeneous cancer types and imaging protocols.
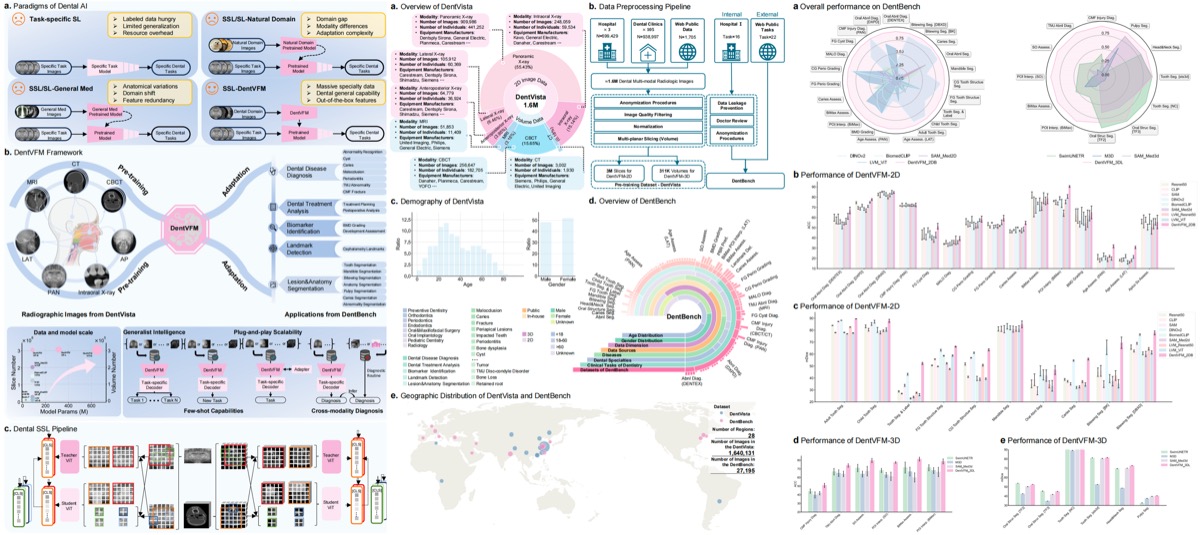
A generalist vision foundation model for dental and maxillofacial radiology, pretrained on large-scale oral imaging data and evaluated across detection, segmentation, and diagnostic classification tasks.
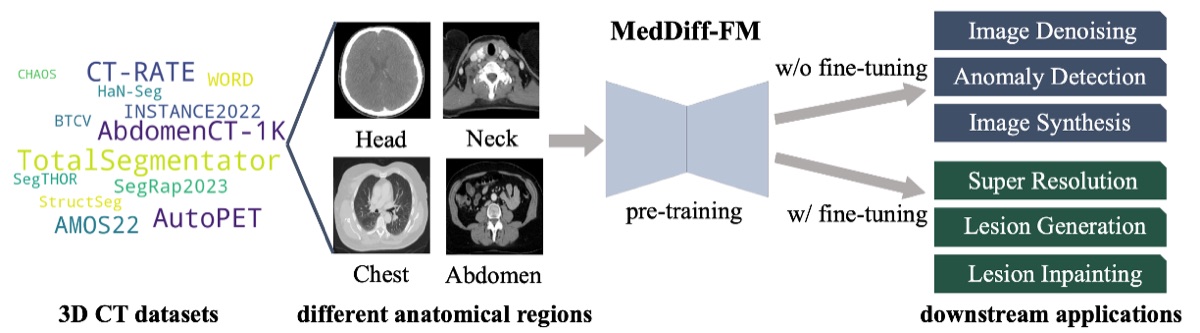
MedDiff-FM: A Diffusion-based Foundation Model for Versatile Medical Image Applications
A diffusion-based foundation model that unifies medical image generation, restoration, and segmentation within a single framework, demonstrating strong generalization across modalities including CT, MRI, and X-ray.
Large Language Models
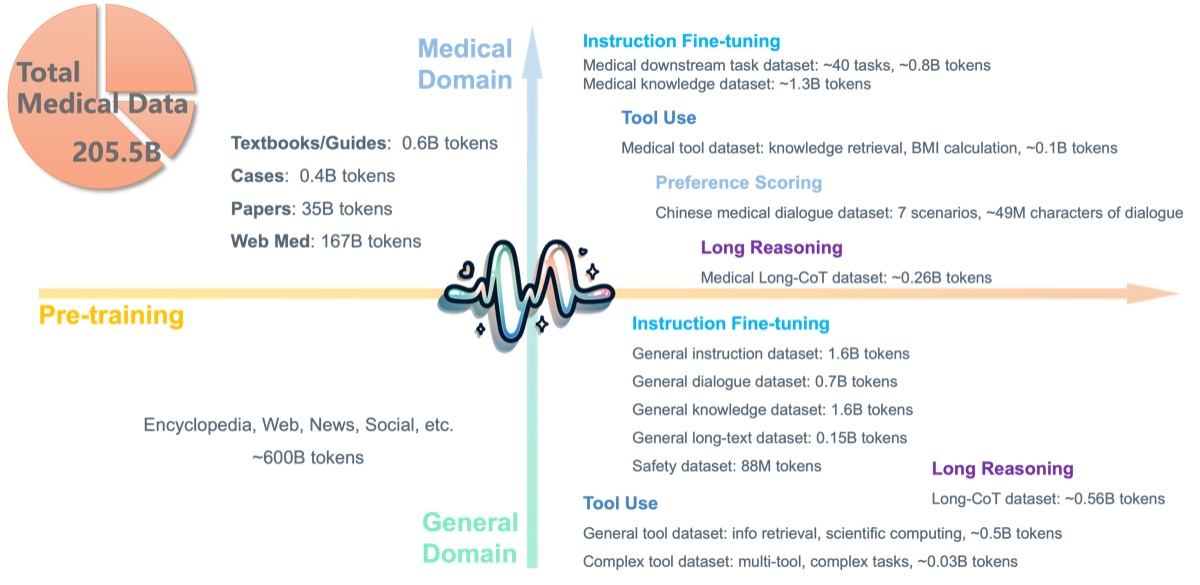
PULSE: Pretrained and Unified Language Service Engine
A Chinese medical large language model open-sourced in 2023 and continuously developed since. PULSE covers a wide range of clinical NLP tasks including diagnosis, drug information, medical Q&A, and report generation, with ongoing expansion of training data and capabilities.
Vision-Language Models
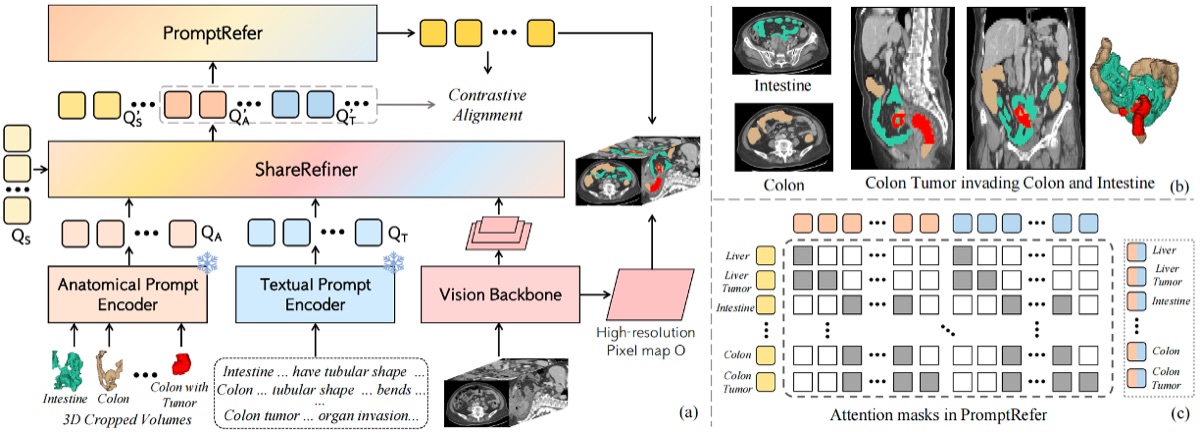
CAT: Coordinating Anatomical-Textual Prompts for Multi-organ and Tumor Segmentation
A vision-language segmentation model that coordinates anatomical and textual prompts to achieve unified multi-organ and tumor segmentation, enabling open-vocabulary queries over 3D medical volumes.
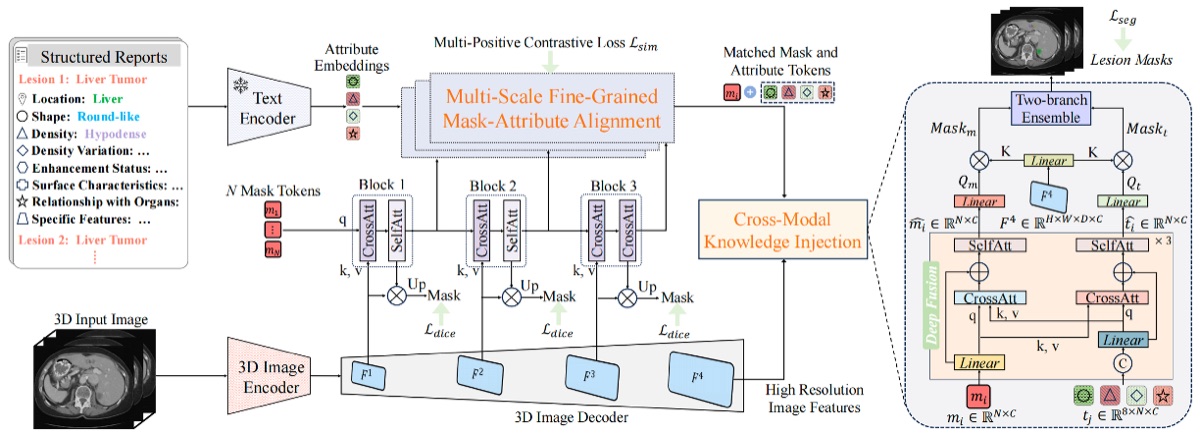
Leverages vision-language pretraining to enable zero-shot lesion segmentation in 3D medical images through mask-attribute alignment, bridging the gap between language descriptions and volumetric spatial understanding.
✦ Vision-language models for medical imaging are a current research focus of our lab — more work coming soon.